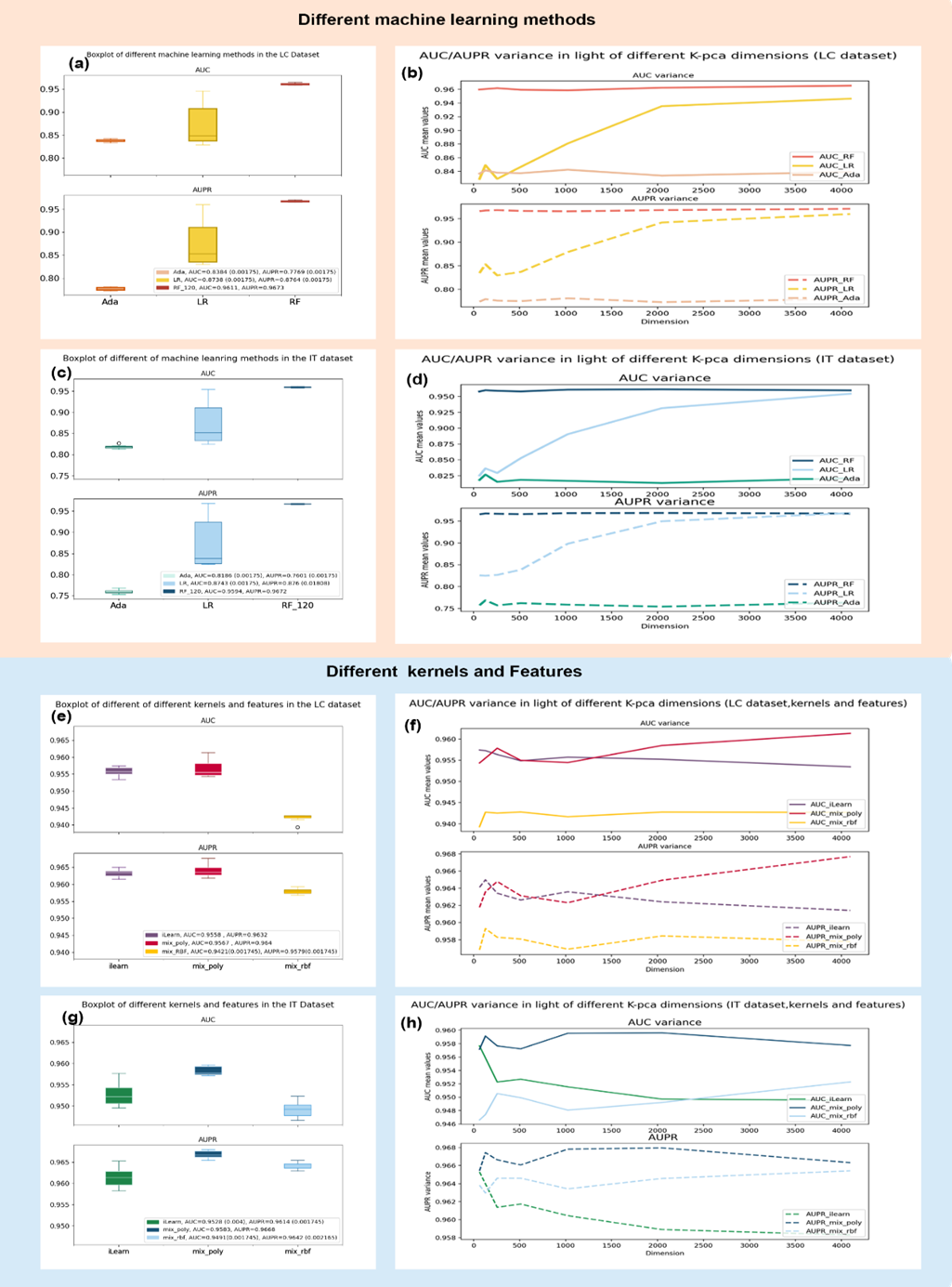
- Model Comparisons
We implemented parameter analysis and altered machine-learning methods, kernels, features, and dimensions. The visualization of the parametric analysis results is shown in Supplementary Fig. S1.
We explored other machine learning methods, including linear classifiers such as Logistic Regression (LR) and non-linear Adaboost (Ada) classifiers. We also performed the rank-sum test on the results and varied the kernel PCA dimensions from 64 to 4096 features. The RF was fine-tuned in the type two cross-validation. To make it fair, we ran 5-fold cross-validations to get the best parameters for LR and AdaBoost and then leveraged the best models for performance comparisons. We conducted experiments on both LC and IT datasets, and the results are shown in Supplementary Fig. S1 (a) and Supplementary Fig. S1 (c). The fined-tuned RF (with a tree number of 120, red, and dark blue) in the LC dataset attained the highest AUC/ AUPR values among all dimensions. The average AUC/AUPR was also significantly outperformed by other methods with p=0.00175. The fine-tuned RF could achieve the best performance regardless of dimensions in the IT dataset. The RF’s AUC values were significantly higher than those of LR (yellow) and Ada (pink) with p=0.00175, and RF’s AUPR values were significantly larger than LR (light blue, p =0.01808) and Ada (light green, p =0.00175).
- Different Feature Transformation Methods
Different Kernels of the kernel PCA might influence the final quality of the features. We tested two kernels: the RBF kernel and the Poly kernel. Each number was the mean value of AUC and AUPR of the different feature dimensions. Details are illustrated in Supplementary Fig. S1 (e) and Fig. S1 (g). Supplementary Fig. S1 (e) is for the LC dataset, and Supplementary Fig. S1 (g) is for the IT dataset. As we can see from the pictures, mixed features with poly kernels (mix_poly, red and dark blue) for LC and IT datasets can achieve significantly higher AUC and AUPR values than RBF kernels (mix_rbf, yellow and light blue) do. In addition, by introducing additional features such as k-mer features, the LC dataset can achieve a significantly higher AUPR value and mean AUC value than in previous settings. In terms of AUC/ AUPR, for the LC dataset, mix_poly and iLearn (purple and green) were significantly better than mix_rbf with p= 0.0017. For the IT dataset, mix_poly was significantly better than RBF and iLearn, with p-values equal to 0.00175 and 0.004. IT AUPR mix_poly was significantly better than RBF and iLearn, with p-values equal to 0.00217 and 0.00175. Thus, we finally chose the mix_poly setting to train models and predict potential relations in the controlled deep-learning approaches.
- Different dimensions
We further explored how dimensions influence AUC/ AUPR values. The results of different dimensions are illustrated in Supplementary Fig. S1 (b), Supplementary Fig. S1 (d), Supplementary Fig. S1 (f), and Supplementary Fig. S1 (h).
For different machine learning methods, RF outperformed other methods along with different dimension settings (Supplementary Fig. S1 (b) with the line in orange, and Supplementary Fig. S1(d) with the line in dark blue). LR is a simple, non-linear classifier. The AUC/AUPR results of LR are shown in Supplementary Fig. S1 (b) with the line in yellow and Supplementary Fig. S1(d) with the line in light blue.
As the dimensionality increased, the performance of LR was constantly improved until the dimensions reached 4096, reflecting that higher dimensions can lead to linear separable planes for the kernel PCA with mixed features.
For the iLearn-kPCA features in the LC dataset (Supplementary Fig. S1 (f), purple), the AUC/AUPR values decreased at the threshold of 1024 dimensions. For the iLearn-kPCA features in the IT dataset (Supplementary Fig. S1 (h), green), we can see that the 64-dimensional features could lead to the highest AUC and AUPR values. As the dimensionality increased, the AUC and AUPR values decreased, indicating that more noise will also be introduced when more features are leveraged if iLearn is the only source of features. Furthermore, by introducing k-mer features, the performance is less influenced.
For the mix-kPCA features, in the LC/ IT dataset, mix features with the poly kernel (Supplementary Fig. S1 (f) red and Supplementary Fig. S1 (h) dark blue) performed better than the RBF kernel (Supplementary Fig. S1 (f) yellow and Supplementary Fig. S1 (h) light blue) along different dimensions. However, the AUC/AUPR values peak in the 4096 dimensions for the LC dataset, while for the IT dataset, the best score was obtained at the 2048 dimensions. Therefore, the mix-poly-kPCA features with 4096 dimensions should be chosen as it has the best performance in the LC dataset and relatively good performance in the IT dataset.